|
I recently had my first grad school paper published! This paper describes software that my colleagues and I created for integrating high-throughput biological data, or "omics" data. The software is called Omics Integrator. The bulk of this work was done when I first joined the lab, in the summer of 2013, and the intervening years have involved a lot of tweaking, improving, and paper submitting. 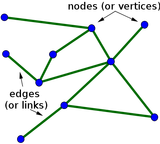 Biologists have a habit of labeling assays which measure a whole species of molecules "omic" assays. You've probably heard of "genomics." Well, there is also "epigenomics" ("over the genome", or measurements of marks and structure of the DNA), "transcriptomics" (measurements of transcripts of RNA), "proteomics" (measurements of proteins), and many more. All of these assays result in hundreds of thousands of data points, and biologists nowadays often do more than one of these assays. That's often too much data for a human brain to make sense of, and even when you can, the different assays can often disagree with one another, since they are interrogating different parts of the system within a cell.
Enter Omics Integrator. The software is designed to take in data from several kinds of omic assays, and to output a "network". In this case, networks are made of "nodes" that stand for proteins, and "edges" that connect proteins which physically interact inside the cell. Omics Integrator outputs nodes and edges which were implicated by your input omics data. These networks are a lot easier to understand. They also often include new nodes - hidden nodes - which didn't show up in your omic assay, but may be very relevant to the cells you were studying. In many cases, you can use these networks to find novel pathways of interacting proteins which are important to your system, whether that system is cells with a human disease, mice which were raised in different environments, or any experiment you've done in your lab. Finding pathways of interacting proteins is a good way to identify which processes have changed in your experiment, and to focus future experiments on that process. If you're studying a disease, pathway identification can help you decide on a drug to try in that disease, or on a drug target. We've tried to make this software as flexible as possible so that it will be useful for any biologist with too much omic data and not enough results. If you want more details on all the math and computation in the software, read our paper (it is published in an Open Access journal, which means you don't need to pay to read it. Open Access publishing could probably be another blog post of it's own). If you're a scientist who wants to try out the software, check it out on our lab website or GitHub page!
1 Comment
6/19/2019 12:18:44 am
It is interesting that you were able to develop this kind of program. To be honest, I view software applications as the best part of our modern society. In the past, most of us need to use traditional means, and by that, I mean much more difficult-to-use processing methods. While they are good, they are not as accurate as software programs. I sure do hope, that you can enhance this software program of yours, from what I can see, this has promise. Leave a Reply. |
AuthorAmanda Kedaigle's work in the Broad Institute focuses on leveraging brand new biological data modalities to study novel models of human brain development. Archives
February 2022
Categories |
 RSS Feed
RSS Feed